MedGUIDE uses big data analytics to analyze the heterogeneous and distributed streams of monitored data regarding patients with dementia, to establish the baseline of daily life activities and to detect deviations. These deviations represent changes, either sudden or gradual, which may signal progression of symptoms, wellbeing decline or side effects of medication. Dr. Tudor Ciaora, coordinator of the MedGUIDE technology and services development, explains the project technical approach in today’s blog post.
The Monitoring Service deals with monitoring and integration of various variables and distributed data sources describing the elder’s activity of daily life & lifestyle and medication intake & adherence to the prescribed therapy. The data flow management is achieved using a Confluent streaming platform featuring: (i) Zookeeper as centralized service used for maintaining configuration information, distributed consistent states and synchronization, (ii) Kafka for building real-time data streaming pipelines, (iii) Kafka Connect for integration with the master data set which is kept in a Cassandra database (NoSQL database for storing time series data from sensors) on which big data techniques will be executed through the Apache Spark engine. The Schema Registry stores all the enforceable schemas while AVRO is used as serialization framework the exchange of messages being done through REST proxies.
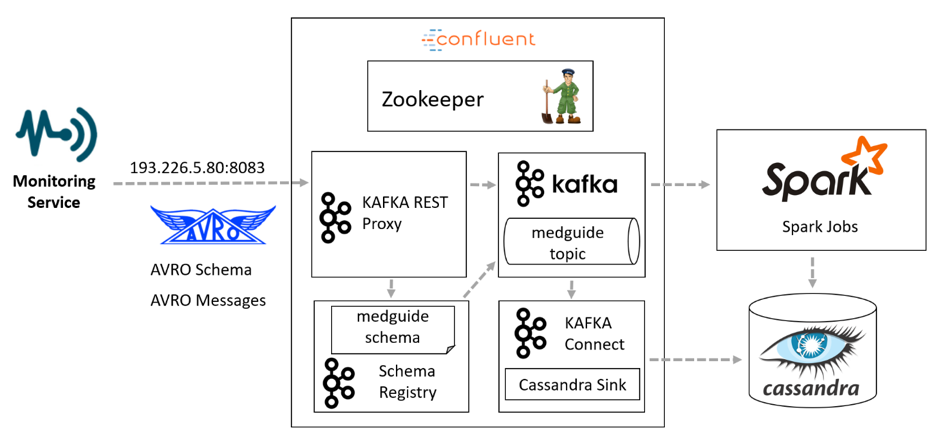
The first version for the MedGUIDE big data assessment service prototype has been released leveraging on three machine learning algorithms implemented as Spark jobs: (i) Random Forest – for the detection of daily life activities baseline, (ii) K-Means – for the detection of the deviations and (iii) Decision Tree – for evaluating the patient adherence to the medication plan. In preparation of the field trials, the prototype will first be validated in a laboratory setting.